Before start reading this blog you should be clear on the below topics
- ANN
- Deep learning frameworks
- How to deal with Categorical data
- Cross validation and Parameter tuning
In this tutorial we will see how to use Keras for classification problem and we will also learn how to use cross validation and Cross Validation/parameter tuning for bias trade off.
We will take the banking data which consist of customer churning data and the column Exited will says if the customer is with bank or not (1 says No and 0 says Yes).
Below are the columns present in the dataset we are using
- CreditScore – This will talk about customer credibility
- Geography – The location where customer lives
- Gender – either male or female 🙂
- Age – Age of the customer
- Tenure -tenure of customer stats
- Balance – total balance in customer account
- NumOfProducts – How many products you have like loan,credit card etc..
- HasCrCard – if customer has credit card or not
- IsActiveMember – if the customer is active or not
- EstimatedSalary – His total income
- Exited – If the customer stays or not
- RowNumber – some unique number
- CustomerId – Customer identity number
- Surname – customer surname
you can download the the data set from here
If you see the data set columns like RowNumber, CustomerId and Surname wont make any sense for any of the Machine Learning models, so we need to remove those columns after reading the data.
We are using pandas here for ETL(Extraction(reading),Transformation(Data pre processing),Loading(storing transformed data in to target)). Below is the code snippet to read the CSV file and delete the unwanted columns
In the below code of you see we are using axis and inplace, axis defines weather it is column or a row (if axis=1 its column and axis=0 its row) and inplace=True says what ever we are doing the changes store it.
Code Snippet 1:

As usual data pre-processing is one of the important thing in any Data science projects in our case we are doing basic data pre-processing steps here.
In our case we are not dealing with dimension reduction/filling missing values etc… we are only doing Label/one hot encoding, reason we are doing this is because not all ML/DL algorithms will understand only numerical data (Algorithms like Decision tree/Random forest will accept categorical data)
We have majorly two different types of encoding
- Label encoding
- One hot encoding
Code Snippet 2:

If you notice the code snippet 2 line two we are calling the function that reads the CSV file and returns the data refer code snippet 1
As usual once we do the data per-processing, we have to split our data for training and testing, as we know training data is to train our model and testing data to test our model how much it learned, and using this two data sets we can also check over fitting and under fitting,
Code Snippet 3:

Now the interesting part comes how to build Neural network for our classification problem.
in this use case we are using the combination of sklean(For parameter tuning and Cross validation score) and keras(For Artificial Neural Networks) packages, First we will see how to build ANN using Keras and then we will use sklearn keras wrapper to use Cross validation and hyper parameter tuning.
To build ANN using Keras we need to import below two packages
from keras.models import Sequential from keras.layers import Dense
The sequential method allows you to create models layer-by-layer for most of the problems like classification . It is limited in that it does not allow you to create models that share layers or have multiple inputs or outputs,we can also say it is a linear stack of layers. In our case Sequential is more than enough.
Dense method will helps us to add layers in a sequential model we can add like how many neurons we need , activation function, input and output dimensions etc…
Code Snippet 4:

If you see the above code we first created classifier object for Sequential method and the ad d method is used to add the Dense layer for the classifier object(means adding neurons or hidden layer).
Blow is the explanation for the parameters of the Dense layer.We have few more parameters but for our use case we are using below ones
- Units : Number of neurons we need in the hidden layer
- Kernel_initializer: This is one of the important parameter that will help us to add weights to our model, In our case we are using uniform
- activation: This is very important parameter in all deep learning models this will add the non linearity to the model we have many activation functions in this use case we are using relu in the hidden layer and sigmoid in the final output layer
- input_dim: This parameter will tell my model that how many columns I have in my datset
Now we have to import KerasClassifier a wrapper for sklearn from keras package as below, this will help us to use Cross validation and grid search for ANN using Keras
Code Snippet 5:
from keras.wrappers.scikit_learn import KerasClassifier
From the above import we will create an object for classifier and we will refer the function we created for building ANN as shown in Code Snippet 4:
Code Snippet 6:
classifier = KerasClassifier(build_fn = build_ann_classifier)
Now in our case parameters we can tune are batch size, epochs and optimizer, now lets build a dictionary for the best parameters.
Code Snippet 7:
parameters = {'batch_size': [25, 32],
'epochs': [100, 500],
'optimizer': ['adam', 'rmsprop']}
Now lets create an object for Grid Search by importing below function, If you notice the below code we have on parameter CV in GridSearchCV which is Cross Validation, so withthe below code we are achieving both Grid Search and Cross Validation and estimator parameter is assigned to the object we created in Code Snippet 6, for param_grid parameter we assigned the dictionary we created in Code Snippet 7.
Code Snippet 8:
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(estimator = classifier,
param_grid = parameters,
scoring = 'accuracy',
cv = 10)
Now lets get the training data and test data by calling the function that we created Code Snippet 3 as shown below
X_train, X_test, y_train, y_test = traintest_split()
Now we are in the final step to train the model with our train data and the multiple parameter combinations using GridSerach and Cross Validation.
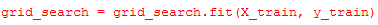
Great now with the help of below methods we can find the best parameters and best accuracy .


Great article! I’m currently working on a series addressing the intricacies of classification-based algorithms. I found this article to raise a particularly fascinating perspective in this regard. Thank you for sharing, I’m looking forward to seeing what you put forth in the future
LikeLike
Thank you
LikeLike