We are taking below famous data which is widely used data set for explaining Decision tree algorithm.

Once we build a decision tree it looks like below.

Now we will see how we achieved above decision tree using Entropy and Information gain matrices.
First and foremost question is, how do I chose my root node as outlook ?
Here is where we use Entropy and Information gain. We need to calculate this for each variable, in our case its outlook, temperature, humidity, wind.play will the variable which we need to predict.
We need to consider the variable with more information gain value as a root node.
For classification use cases:
- Let’s say in my dataset if all predicted/dependent variables are either zero or one then the value of entropy will be zero. Let’s say in our dataset if play variable contains only one value either YES or NO then entropy will be zero which is also called Pure
- If half of the predicted/dependent variables are zero and remaining half is one then entropy will be 1. Let’s say in our dataset if play variable contains equal number of YES and NO values then entropy will be one which is also called impure
Step 1) Calculate Entropy:
First we need to calculate Entropy for our dependent/target/predicted variable.
In our data set we have 9 YES and 5 NO out of 14 observations.
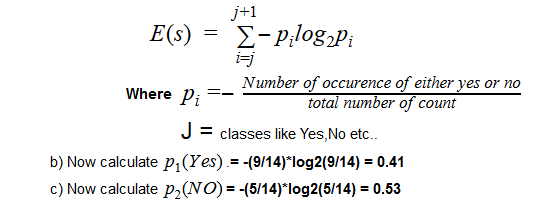

From above equation we got entropy value as E(S)= 0.94
Note:
Less Entropy = Less Information Missing = Greater Certainty = Greater Purity
More Entropy = More Information Missing = Less Certainty = Less Purity
In our case we have two class/binary values, if we have more then two class we also need to calculate for them, like what we did for p1(Yes) and p2(No)
Step 2) Calculate Information/average entropy and gain:
Information gain can be defined in many ways in simple, measures the impurity of the individual variables .
We need to calculate information and gain for each and every variable, which ever variable is giving high value we will consider it as root node.
Lets calculate Information gain for outlook, we need to group the data based on the categorical values in our case it is sunny,overcast and rainy as shown in below Image.

Fig:3
Below is the formula to calculate the Weight of Evidence or Information or Average Entropy.

Gain = G(Outlook) = Entropy – Information = E(S)-I(Outlook) = 0.94-0.693 = 0.24 (We calculated E(S) in step1)
Now we got the Gain value for Outlook is 0.24
similarly calculate for temperature, humidity and wind and results as shown below.

If we see the above screenshot Outlook has more Information Gain, so we are considering it as root node.
Now our tree looks like below.As Outlook had three categorical variable(Sunny, Overcast, Rainy)

we also need to consider the remaining variables as part of our decision tree, Now how do we select the remaining variables.
As we know we have three variables left temperature, humanity and wind, we need to calculate Information gain.
To calculate the information Gain for the remaining variables, we need to group the data based on Sunny, Overcast and Rainy as shown below(These are the three different observations) and then calculate information gain for Sunny, Overcast and Rainy. Why Sunny,Overcast and Rainy because they are the immediate node after outlook root node.
GroupBy Sunny.

Refer Step1 and Step2 to calculate Entropy and Information gain. As shown in the above screenshot here we have 2 Yes and 3 No out of total 5 observations, based on this values we need to calculate Entropy and Information gain.
Results below

As per the above results we have highest value for Humidity for Sunny,So our decision tree will looks like below

GroupBy Overcast:

Since all the values for play is unique(all YES in our case), the entropy will be zero we can also called this node as pure.
Now to get the Gain the formula is Entropy – Information as entropy value is zero Gain will be in negative for temperature, humidity and wind so there is no further split for Overcast.
Our decision tree will looks like below.

GroupBy Rainy:

Again we need to find Gain for all three variables temperature, humidity and wind, in this case wind has more Gain so that will be our split.
Our decision tree will looks like below.

Similarly we again need to calculate Gain for humidity and wind, and in the similar way we need to decide the split.
The final decision tree will looks like below.
Note:
- We can also calculate information gain using Gini or Classification error same as we did for entropy.
- We can also call this method as iterative
- If the subset is “pure”, the splitting will stop. If it is “impure” the algorithm will continue to split the subsets until every subset is “pure.” Once this is done, the decision tree is complete.
How to predict the new outcome with the help of above final Decision tree

One thought on “Deriving Decision Tree using Entropy (ID3 approach)”