In a given dataset that contains class for the predicted/dependent variable (like Yes,No,Neutral etc..), we can measure homogeneity or heterogeneity of the table based on the classes.
- We say a dataset is pure or homogeneous if it contains only a single class(either YES or NO).
- If a dataset contains several classes, then we say that the table is impure or heterogeneous(Combination of YES and NO).
There are several ways to measure degree of impurity. Most well known ways to measures are given below .
- Entropy
- Gini index
- Classification error
There respective formulas are given below.


In our below dataset we have two classes YES and NO and we have 9 YES and 5 NO out of 14 observations.
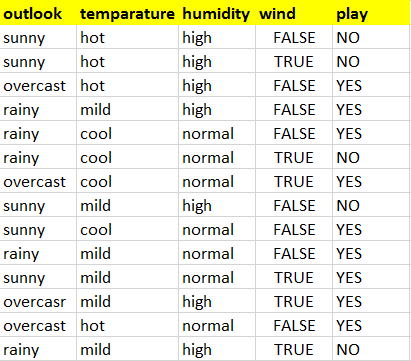
Let’s calculate the probability for the class YES and NO
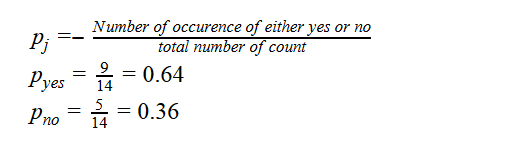
For the above data set the the values for entropy, Gini and classification error as below
- Entropy = 0.94
- Gini = 0.46
- Classification error = 0.36
Oh wondering how we got above values Lets do it hands on!
Entropy:
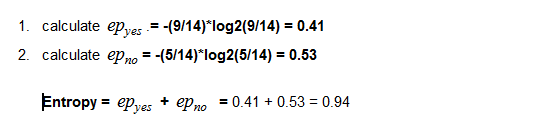
Gini:
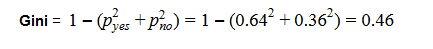
Classification error:
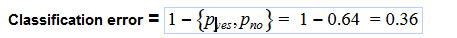
In the above formula we took the max value as per the equation.
